
Abstract
Plasmids are major drivers of gene mobilization by means of horizontal gene transfer and play a key role in spreading antimicrobial resistance among pathogens1,2. Despite various bacterial defence mechanisms such as CRISPR–Cas, restriction–modification systems and SOS-response genes that prevent the invasion of mobile genetic elements3, plasmids robustly transfer within bacterial populations through conjugation4,5. Here we show that the leading region of plasmids, the first to enter recipient cells, is a hotspot for an extensive repertoire of anti-defence systems, encoding anti-CRISPR, anti-restriction, anti-SOS and other counter-defence proteins. We further identified in the leading region a prevalence of promoters known to allow expression from single-stranded DNA6, potentially facilitating rapid protection against bacterial immunity during the early stages of plasmid establishment. We demonstrated experimentally the importance of anti-defence gene localization in the leading region for efficient conjugation. These results indicate that focusing on the leading region of plasmids could lead to the discovery of diverse anti-defence genes. Combined, our findings show a new facet of plasmid dissemination and provide theoretical foundations for developing efficient conjugative delivery systems for natural microbial communities.
Similar content being viewed by others

Main
Conjugation is a primary horizontal gene transfer mechanism in which DNA is transferred between microbial cells. Conjugative plasmids drive rapid bacterial evolution7 and present a major challenge in combating the spread of antimicrobial resistance genes (ARGs)1,2.
Conjugative elements’ transport machinery comprises type IV secretion system (T4SS) proteins, an origin of transfer (oriT) and a relaxosome (a relaxase, often with auxiliary proteins)8. Whereas conjugative plasmids and integrative conjugative elements (ICEs) encode for the entire transport machinery, mobilizable plasmids, containing only relaxosome components and oriT (refs. 9,10), rely on coresiding conjugative elements for transfer11. We refer to both types as ‘potential conjugative elements’, as they can be transferred by conjugation12. Conjugation is initiated with the assembly of the relaxosome at the oriT and the nicking of the nic site within the oriT (ref. 8). The nicked DNA strand (T-strand) is transferred into the recipient cell, and the first transferred region is termed the leading region. The relaxase is typically located in the lagging region, which enters the recipient cell last13,14.
Previous studies suggested that the leading region genes are important for plasmid establishment during conjugation15,16. In certain plasmids, these genes are expressed early on entry into the recipient cell17,18,19, preceding the conversion of the entering single-stranded DNA (ssDNA) into double-stranded DNA (dsDNA)20. The regulation of some of these genes involves unique promoters designated Frpo, which adopt a secondary structure that mimics a double-strand conformation, allowing recognition by the host RNA polymerase6,17. Thus, Frpo functions as a single-strand promoter, enabling early expression of leading region genes20.
Conjugative elements face various prokaryotic defence systems, including restriction–modification and CRISPR–Cas3,21. Despite these defences designed to prevent the entry of exogenous DNA, horizontal gene transfer widely persists across bacterial species4,5. This is enabled, among other factors, by anti-defence mechanisms such as anti-restriction and anti-CRISPR genes developed by mobile genetic elements (MGEs)22,23. A few of the genes described in plasmids’ leading regions encode anti-defence proteins, such as ArdA, an anti-restriction protein24, and PsiB, which inhibits the bacterial SOS response25, and are known to be early expressed18. However, these studies were performed on very few genes and plasmids (IncI, ColIb-P9 and F plasmids). Most of the leading region genes and their function during conjugation remain largely unexplored26,27.
We investigated the leading region’s role in conjugative elements’ ability to evade host defences. We proposed that for anti-defence genes to be effective, they need to be rapidly expressed in the very early stages of conjugation28, reminiscent of early expression of anti-CRISPRs and the ocr anti-restriction gene reported in phages29,30. In line with this hypothesis, we discovered that the leading regions of conjugative elements are highly enriched with anti-defence genes and that these regions contain various uncharacterized genes, many of which are probably anti-defence related. Our results indicate that the leading regions act as ‘anti-defence islands’, protecting conjugative elements from host defences upon entry to recipient cells.
Anti-defence genes in the leading region
We analysed all sequences annotated as plasmids in the National Center for Biotechnology Information’s (NCBI) Whole-Genome Shotgun (WGS) database to explore the position of anti-defence genes relative to the oriT (workflow overview in Extended Data Fig. 1a). We focused on plasmids with an oriT adjacent to a relaxase/traM gene, allowing us to discern the leading and lagging regions, as these relaxosome genes are typically encoded in the lagging region near the oriT (refs. 13,14) (Extended Data Fig. 1b). The plasmids were detected by seeking homology to experimentally validated and predicted oriTs, followed by locating a relaxase/traM relaxosome gene and anti-defence genes using profile hidden Markov models (pHMMs). Anti-defence profiles included anti-CRISPRs antagonizing CRISPR–Cas systems22, anti-restriction proteins inhibiting restriction–modification endonucleases23,31 and SOS inhibitors suppressing the host SOS response elicited by plasmid entry.
Measuring the relative abundance of anti-defence genes at each position relative to the oriT location revealed that leading regions are highly enriched with anti-defence genes (Extended Data Fig. 2a). Specifically, most of the first 30 open reading frames (ORFs) in the leading regions were significantly enriched with anti-defence genes (one-sided Fisher’s exact test, α = 0.001).
To assess the generality of this phenomenon, we expanded the dataset beyond explicitly annotated plasmids (which did not include ICEs and were biased towards pathogens and model organisms). We thus searched all publicly available genomic and metagenomic assemblies from NCBI and European Bioinformatics Institute (EBI) for potential conjugative elements by identifying contigs with relaxase/traM genes in proximity to an oriT. Within the 26,327 additional non-redundant potential conjugative elements detected, we again observed anti-defence gene enrichment in the leading region. However, a notable proportion of these genes was also identified in the lagging region (Extended Data Fig. 2b). Dissecting the dataset by mobilization (MOB) types showed significant enrichment (one-sided Fisher’s exact test, α = 0.001) of anti-defence genes in leading regions across most MOB types. However, MOBT, MOBP2 and MOBC showed no discernible anti-defence gene enrichment in the leading regions (Extended Data Fig. 2b) and were omitted from downstream analysis. Notably, uneven distribution of MOB types across bacterial phyla and mobile element types32 suggests variations in conjugation mechanisms and interactions between host defences and plasmid anti-defences. For instance, the MOBT type, common in ICEs and widely distributed within Firmicutes33, shows unique relaxase characteristics34 that may influence the function of the leading region.
The combined set of well-characterized plasmids and potential conjugative elements comprised 27,677 non-redundant sequences. Excluding the three MOB types with no significant enrichment in the leading region left 21,907 sequences. In this dataset, most of the 29 leading positions were significantly enriched with anti-defence genes (Fig. 1a and Extended Data Fig. 2c; one-sided Fisher’s exact test, α = 0.001). Analyses of each anti-defence category showed similar trends (Fig. 1b). This demonstrates that, across diverse conjugative elements from a wide range of bacterial hosts (Extended Data Fig. 3), the genes first transferred are disproportionately enriched with anti-defence functions.

a, Anti-defence gene frequency in 21,907 plasmids and potential conjugative elements (MOBs F, P1, Q, V, H, B). The x axis shows ORF indices relative to the oriT, with 0 representing the first ORF in the leading region. Only positions represented in at least 500 sequences are shown (additional positions in Extended Data Fig. 2c). The y axis indicates the average frequency of anti-defence genes (combining SOS inhibition, anti-restriction and anti-CRISPR genes) over a five-ORF window. b, Breakdown of anti-defence gene frequency by functional category. c, The 100 largest gene families significantly enriched in the leading regions (one-sided Fisher’s exact test, α = 0.001 after FDR correction for multiple testing), categorized into six groups: (1) anti-defence genes, which are anti-CRISPRs, anti-restriction genes and SOS inhibitors; (2) DNA methyltransferases (MTases); (3) toxin–antitoxin genes; (4) SSBs; (5) other, which are annotated genes with no known association to anti-defence and (6) uncharacterized genes. The y axis shows the family size, whereas the x axis shows the families ranked on the basis of their size. Note that some of the most prevalent families are not enriched specifically in the leading region and are thus omitted from this analysis. Diamonds indicate gene families encoded opposite to the T-strand, which cannot be transcribed from the leading ssDNA. Putative annotations are indicated with striped bars. Structural comparison between a DNA-methyltransferase from Escherichia coli (gene family 8, NCBI accession CP029982.1) and a putative DNA-methyltransferase from E. coli (gene family 14, NCBI accession MCJK01000027.1) are presented above the respective families. The inset focuses on the 20 largest gene families (Supplementary Table 1).
Roles of abundant leading region genes
To better understand the function of prevalent gene families in the leading regions, we clustered genes from anti-defence-enriched locations within the 21,907 non-redundant conjugative elements. We then identified gene families specifically enriched in the leading region, by comparing their prevalence to other regions on the same contigs. This analysis revealed that 255 of the 300 largest families were significantly enriched in the leading region (one-sided Fisher’s exact test, α = 0.001, Supplementary Table 1).
Focusing on the 100 largest gene families significantly enriched in the leading region revealed three main functional groups beyond known anti-defence genes (Fig. 1c). One of the most prominent functions was ‘orphan’ DNA-methyltransferases (MTases), potentially protecting conjugative elements from host restriction–modification systems. This protective role of orphan MTases has been previously demonstrated in phages35,36,37 and more recently also observed in plasmids in which MTases encoded on the pESBL plasmid methylate entering ssDNA early in conjugation38.
SSBs (ssDNA-binding proteins) were also frequently encoded in these regions, often adjacent to SOS inhibitors (psiA and psiB). Plasmid-encoded SSBs are important for effective SOS inhibition by PsiB39,40 and may aid in evading host CRISPR–Cas systems by facilitating dsDNA break repair41. SSBs also protect ssDNA intermediates from nuclease degradation and interact with various bacterial genome maintenance proteins, including recombination, repair and replication factors42. These functions suggest multiple protective roles during early conjugation stages, alongside other possible roles in the newly transconjugant cells, including involvement in plasmid duplication20.
Toxin and antitoxin genes, both as part of complete toxin–antitoxin systems and as orphan antitoxins, were also highly represented in the leading regions. Although toxin–antitoxin systems are encoded throughout conjugative element genomes, their overrepresentation in leading regions suggests a potential protective role in conjugative element establishment (Supplementary Discussion).
Notably, 33% of the 100 most prevalent gene families in leading regions were uncharacterized (Fig. 1c). Given the considerable overrepresentation of anti-defence genes in this region, many of these families probably have anti-defence-related functions. Investigating the largest unannotated families revealed potential anti-defence roles (Extended Data Table 1 and Supplementary Table 1). To further explain these functions, we conducted structural analyses of 107,893 proteins belonging to uncharacterized families enriched in the leading region and primarily encoded on the T-strand. This analysis uncovered potential anti-defence genes undetectable by sequence similarity, including putative anti-CRISPRs (for example, acrIIA8, acrVA5 and acrIB) and anti-restriction genes (for example, darA and ardA, Extended Data Fig. 4 and Extended Data Table 1). The structural analysis further underscored the prevalence of MTases, SSBs and toxin–antitoxin genes within the leading region of plasmids. Phage-associated annotations were found in nearly 10% of the analysed gene families, suggesting shared anti-defence mechanisms between plasmids and phages.
Anti-defence islands
We noticed that anti-defence genes in plasmids’ leading region tended to cluster into islands (Fig. 2a–d and Extended Data Fig. 5a–d), as previously reported for MGEs with clustered anti-defence genes43. We refer to these as islands because most annotated genes in these clusters share similar functions and reside between defined boundaries: the oriT on one end and often umuCD homologues on the other (Extended Data Fig. 5e,f). These islands contained different combinations of adjacent anti-defence genes and genes potentially protecting invading DNA such as MTases and SSBs. For example, we identified an island in the leading region of a Salmonella enterica conjugative element containing two anti-CRISPRs (acrIC6 and acrIF16) near an anti-restriction (klcAHS), SOS inhibitors (psiA and psiB), MTases, SSBs and a toxin–antitoxin system (higB-higA, Fig. 2a). A similar island in the leading region of a Serratia marcescens plasmid harboured an anti-CRISPR inhibiting a different type of CRISPR–Cas system (acrIE9) and an additional antitoxin gene (hipB, Fig. 2b). The hipB antitoxin, typically countering HipA toxicity as part of hipBA operons44, was found next to a higA/relE toxin–antitoxin system in this island. It may function as an orphan antitoxin inhibiting competitive MGEs or host toxin–antitoxin defence systems (Supplementary Discussion).

a–d, Representative anti-defence islands from leading regions of conjugative elements in: (a) Salmonella enterica (NCBI assembly accession AAEPNF010000010.1), (b) Serratia marcescens (NCBI accession CP047692.1), (c) an insect metagenome (NCBI accession OFEI01000013.1) and (d) Streptococcus pneumoniae (NCBI accession CPMX01000004.1). The oriT location is marked in red on the left. Genes are colour-coded by functional category: anti-defence (red), MTase (peach), toxin–antitoxin genes (orange), SSB (yellow), mobility (transfer genes, blue), other (gene without known association to anti-defence, teal), uncharacterized genes enriched in the leading regions (grey), other uncharacterized genes (white). Asterisks (*) next to gene annotations indicate a potential anti-defence function. Frpo promoters are indicated by arrows: a solid arrow for promoters with significant similarity to known Frpo sequences, a dashed arrow for Frpo candidates and dashed with an asterisk (*) for low-certainty candidates. Further islands are presented in Extended Data Fig. 5. e, Predicted secondary structure of the Frpo in S. marcescens plasmid from b. f, Putative Frpo candidate in the conjugative element from c. Regions corresponding to the −10, −35 and UP elements, as well as their complementary regions, are coloured and highlighted above the structure, along with the canonical sequences of these elements. Uppercase letters indicate nucleotides conforming to canonical sequences of the −35 and −10 elements (5′-TTGACA-3′ and 5′-TATAAT-3′, respectively; full sequences in Extended Data Fig. 6b,c).
Many of the islands were flanked by an operon of umu-like genes, forming the island’s terminating boundary (Extended Data Fig. 5e,f). These genes are plasmid homologues of umuC and umuD, which encode chromosomal translesion DNA synthesis polymerases (DNA polymerase V)45. Although widespread in conjugative elements46,47 and other MGEs, including the conjugative transposon Tn5252 (ref. 48) and phages49,50, their role in plasmids remains unclear51. Despite their high abundance in the leading region, 90.3% are not oriented for transcription from the T-strand, suggesting they are not expressed early in conjugation. Notably, one of the anti-defence islands we detected seemed to consist of two adjacent islands separated by a transposase, with umu-like gene operons flanking each of these adjacent islands (Fig. 2c).
Using uncharacterized gene families enriched in the leading regions, we detected more putative anti-defence islands. One such island, originating from a conjugative element from the Gram-positive pathogen Streptococcus pneumoniae, included two anti-CRISPRs (acrIB1 and acrIIA21), two darB anti-restriction genes, an MTase, a toxin–antitoxin system (abiEii-abiEi), two uncharacterized gene families prevalent in leading regions and an spxA gene (Fig. 2d). SpxA represses X-state, a stress-response mechanism inducing competence in S. pneumoniae (a species lacking a classical SOS-response pathway)52. MGEs reportedly disrupt competence genes53,54, preventing exogenous DNA uptake that could presumably contribute to MGE elimination55. The plasmid-encoded SpxA may thus serve as an ‘anti-X-state’ protein preventing stress response, akin to SOS inhibitors found in other plasmids.
ssDNA promoters in anti-defence islands
Analysis of the 300 most prevalent gene families enriched in the leading region showed that all anti-defence genes, MTases, SSBs and toxin–antitoxin genes were encoded exclusively on the T-strand (Fig. 1c). This orientation suggests potential transcription from the strand first transferred to the recipient, even before synthesis of the plasmid’s complementary strand.
Specific promoters, known as Frpo or ssi, which create secondary DNA structures mimicking dsDNA, can facilitate transcription from ssDNA17,38. We searched known Frpo/ssi sequences in the leading regions of the 21,907 potential conjugative elements, detecting 13,089 Frpo-homologous promoters in 6,006 conjugative elements. In the leading regions of S. enterica and S. marcescens plasmids, we identified one Frpo-like sequence immediately upstream of an SSB gene (Fig. 2e). Notably, Frpo transcription is highly stimulated by SSB6. These Frpo sequences in S. enterica and S. marcescens show roughly 89 and 80% identity, respectively, with an F plasmid Frpo upstream of an SSB gene demonstrated to be early transcribed from ssDNA20.
In the insect metagenome and S. pneumoniae islands, no sequences with significant similarity to Frpo were found. We thus conducted a more sensitive search for Frpo-like candidates upstream of ORFs in these islands, on the basis of the conformance of the predicted secondary structure with known Frpos and the consensus sequences of the −35 and −10 elements (Supplementary Table 2). In the S. marcescens island, we detected three Frpo-like candidates (Frpo’). The search in the S. enterica island yielded three sequences bearing only distant Frpo similarity (Frpo*), showing secondary structures similar to known Frpo but considerable differences in the conserved −35 and −10 elements (Extended Data Fig. 6a). Analysis of the insect metagenome island led to the detection of three Frpo-like candidates (Frpo’, Fig. 2f) and four putative Frpo candidates with only distant similarity to known Frpo sequences (Frpo*). We next searched for the Frpo-like candidates (Frpo’ and Frpo*) within the entire set of leading regions. This analysis identified 7,751 Frpo’ and 950 Frpo* candidates, presenting high and limited similarity to Frpo sequences, respectively. Overall, examination of regions upstream of ORFs in the islands revealed a widespread presence of Frpo-like promoters in anti-defence islands, suggesting they potentially allow early expression from ssDNA during the initial stages of conjugation.
Impact of leading genes on conjugation
We experimentally investigated how positioning anti-defence genes in the leading region of conjugating plasmids’ T-strand affects conjugation efficiency when the recipient bacteria contain a defence system (Fig. 3a). Specifically, we tested conjugation efficiencies of four F plasmid variants transferred to recipients expressing Cas9: (1) with an anti-CRISPR (acrIIA4) under an Frpo promoter in the T-strand’s leading region; (2) with an anti-CRISPR and an Frpo in the T-strand’s lagging region; (3) with an anti-CRISPR and an Frpo in the leading region of the T-strand’s complement and (4) with no anti-CRISPR. We used two recipients: one with a guide RNA (gRNA) targeting the F plasmid, and another with a non-targeting gRNA as a negative control.

a, Schematic representation of the donor and recipient cells during the conjugation experiments. The F plasmid’s T-strand is transferred into the recipient, starting with its leading region. In the recipient, a separate plasmid expresses Cas9 targeting the F plasmid. b, Representative example of transconjugant cell growth for each F plasmid variant. Droplet rows represent serial 1:5 dilutions. c, Conjugation efficiency as a function of the positioning and orientation of the anti-CRISPR acrIIA4 on the F plasmids. Bars indicate the mean conjugation efficiency of each F plasmid variant relative to the control, which is an F plasmid with no anti-CRISPR gene transferred to a recipient with a non-targeting gRNA. Red bars represent recipients with a targeting gRNA, whereas grey bars represent recipients with a non-targeting gRNA. Conjugation efficiency is calculated as the transconjugant frequency (T/(R + T)) per conjugation, divided by the transconjugant frequency of the control (T, transconjugants and R, recipient cells). Data are presented as mean values ± s.e.m. from n = 3 biologically independent experiments. Individual data points from each experiment are overlaid on the corresponding bars.
In the absence of the anti-CRISPR, Cas9 strongly inhibited conjugation in a guide-dependent manner: non-targeted plasmids transferred roughly 550 times more efficiently than targeted plasmids. Plasmids encoding the anti-CRISPR in the leading region under an Frpo promoter effectively overcame Cas9 inhibition, resulting in conjugation roughly 225 times more efficient than F plasmids without the anti-CRISPR. Anti-CRISPRs expressed from the T-strand’s lagging region or the leading region of the complementary strand led to considerably less efficient conjugation compared to expression from the T-strand’s leading region (Fig. 3b,c).
These findings indicate that the localization of anti-defence genes in the leading region is crucial for effectively counteracting recipient defence systems. We postulate that this stems from the need to express anti-defence genes very early during the transfer for efficient conjugation.
Discussion
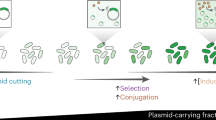
An intrinsic part of the arms race between bacteria and MGEs is the interplay between defence and defence evasion systems. We present a broad and diverse set of plasmid-encoded anti-defence genes, reflecting the vast and dynamic repertoire of bacterial immune systems3. Examination of conjugative elements across extensive genomic and metagenomic datasets revealed a high concentration of anti-defence genes in the leading region. Our experiments confirmed the critical role of this region in overcoming host defences and enhancing conjugation efficiency. Although the genetic region adjacent to the propagation module (that is, mobility genes) and the oriT is at present termed the ‘establishment’ region20,27,56, our findings highlight that inhibiting host defences is a key function of genes in this region. We thus propose designating this region as ‘establishment and anti-defence’ (Fig. 4).

The figure illustrates how anti-defence genes with ssDNA promoters in the leading region can protect plasmids during the very early stages of transfer to a recipient cell. As the bacterial immune response activates defence systems against foreign DNA, various plasmid-encoded genes counteract these defences: anti-CRISPRs can inhibit CRISPR–Cas systems; SOS inhibitors (such as PsiB) can repress the cell’s SOS response by preventing RecA protein activation, thus inhibiting the cleavage of LexA, an SOS-response transcriptional repressor. Single-stranded binding (SSB) proteins, involved in the SOS-response inhibition, may protect transferred ssDNA from host nucleases. Anti-restriction proteins may prevent DNA cleavage by restriction–modification systems. MTases, methylating the transferred DNA can impede recognition by the host restriction–modification (RM) systems; and toxin–antitoxin genes potentially act against competitive MGEs or host defence systems (Supplementary Discussion). The top-right panel shows a schematic genetic organization of a conjugative plasmid. The four main functional gene groups are colour-coded: propagation (blue), adaptation (purple), replication (green) and the anti-defence genes (red) within the establishment module (orange).
Plasmids have been explored as conjugative delivery systems for editing natural microbial communities57 and for various biotechnological applications, such as targeting antibiotic-resistant bacteria using CRISPR nucleases. However, these attempts often resulted in low conjugation efficiency, particularly in complex microbial communities such as the human gut58,59,60. These studies emphasize that improving conjugation efficiency is vital for future applications. Our findings may provide a crucial factor in understanding the set of genetic tools required for efficient conjugation-based delivery systems for medical and biotechnological applications.
Methods
Datasets and initial annotation
The assemblies of all genomes and metagenomes from NCBI whole-genome projects61 and all assembled metagenomes available from EBI MGnify were downloaded on 14 March 2020 (ref. 62). After excluding genomes from Metazoa, Fungi and Viridiplantae, the dataset included 596,338 genomes and 22,923 metagenomes from various ecosystems. This dataset contained more than 45 million contigs of at least 10 kilobase pairs. In WGS, 31,119 sequences were explicitly annotated as plasmids. Gene calling and initial annotation were performed using prodigal63 v.3.0.0 and Prokka64 v.1.14.6. As part of the annotation process, genes were assigned Kyoto Encyclopedia of Genes and Genomes (KEGG) orthologue groups as described in ref. 65. Briefly, all KEGG genes associated with a KEGG orthologue in the KEGG database downloaded on 14 May 2021 were subclustered with MMseqs2 (ref. 66). The pHMM database included all subclusters with more than five members after aligning the orthologues with MAFFT67 and building the model using HMMer suite’s hmmbuild (v.3.3.2)68. MOB classification to types (F, P1, T, V, C, Q, P2, H, B, P3 or M) was performed using pHMMs acquired from MOBscan69. Of these MOB types, P3 and M were not represented in our data.
Relaxase/traM and oriT detection
Detection of relaxase and traM relaxosome genes was performed using hmmsearch68 (e value threshold 10−6) against all the proteins in our dataset. The pHMMs were acquired from Pfam70 and MOBscan69 databases (Supplementary Table 3). Contigs with more than two relaxase or TraM hits were filtered out. Known oriT sequences were retrieved from oriTfinder71 (1,075 oriT sequences), OriT-strast72 (112 sequences) and from ref. 12 (40 sequences). The search was conducted as in ref. 12, with the following differences: our approach incorporated, in addition to the experimentally validated oriTs, also computationally predicted oriT sequences from oriTfinder and BLAST’s word size was reduced to five for increased sensitivity. Specifically, we used BLAST+ (v.2.10.0)73, with an e value threshold of 10−6 and the following parameters ‘-task blastn-short -word_size 5’ against relaxase/traM-containing contigs (11,908 WGS plasmids and 1,019,093 genomic and metagenomic contigs). Known oriT sequences were detected in 5,304 annotated plasmids with relaxase and 238,363 relaxase-containing genomic/metagenomic contigs. In contigs with more than one oriT hit, the best-scoring oriT was considered. The distance between the relaxase/traM gene and the oriT was calculated as the number of nucleotides between the end of the relaxase/traM gene and the start of the oriT. Contigs in which this distance between the two was more than 3,500 bp were filtered out. We included contigs in which the oriT partially overlapped the relaxase gene, but cases in which the oriT was entirely contained within the relaxase gene were excluded. Contigs in which relaxase genes or the oriT were at the first or last annotated sequences were excluded as well. Both these cases were omitted because they impeded our ability to determine the relative location of the oriT and the relaxase/traM gene. Overall, this filtering process yielded 4,441 WGS annotated plasmids and 206,158 potential conjugative elements containing a relaxase/traM gene and an oriT.
Deduplication of redundant sequences
To avoid artefacts resulting from redundant sequences, we clustered all 677,638 ORFs of the 4,441 WGS plasmid contigs containing relaxase and oriT using CD-HIT74 (v.4.6). The percentage of shared ORFs (according to the clustering) for each pair of contigs was calculated. If two plasmids shared more than 90% of the ORFs, the plasmid with fewer ORFs was filtered out. This process yielded 2,259 representative plasmids. This deduplication process was also applied to 206,158 potential conjugative elements identified in genomic and metagenomic sequences, yielding 26,327 non-redundant contigs of potential conjugative elements. Combining the annotated plasmids with the rest of the potential conjugative elements and removing plasmids appearing in both sets resulted in a total of 27,677 non-redundant contigs of potential conjugative elements. The host phylogenetic distribution of these non-redundant contigs (Extended Data Fig. 3) was mapped to the bacterial subtree from iTOL75, which is based on a concatenated alignment of 31 protein families related to translation and transcription76. The tree visualization was generated using ggtreeExtra (v.1.8.1)77.
Anti-defence and mobility gene annotation
Protein families with known anti-defence functions were modelled using 139 pHMMs (based on sequences detailed in Supplementary Table 3). To characterize the plasmid’s transfer genes, we searched for conjugation proteins using pHMMs downloaded from Pfam70 or computed on the basis of proteins from relevant KEGG orthologues78 (Supplementary Table 3). To annotate transposases, we used 49 pHMMs from TnpPred data archive79. Hmmsearch with an e value threshold of 10−6 was performed against the non-redundant set of potential conjugative elements containing a relaxase/traM and an oriT.
Statistical enrichment analysis and ORF clustering
To test which ORF positions in the leading region of plasmids and potential conjugation elements were significantly enriched with anti-defence genes, we performed a Fisher’s exact test (one-sided, P < 0.001) on the anti-defence gene count at each location (anti-defence gene count versus the total number of genes). The enrichment analysis was performed on the 2,259 sequences of well-annotated plasmids for 965 positions with at least 50 ORFs and on each MOB type of the 26,327 sequences of potential conjugative elements. MOB types with at least 50 ORFs in the first ten positions were filtered out if they did not show a significant enrichment in most of these positions. This resulted in the omission of three MOB types: T, C and P2, comprising 5,686 sequences. After removing these MOB types, we continued the analysis focusing on MOB types F, P1, V, Q, H and B, which were identified in 21,907 non-redundant plasmids and potential conjugative elements. For the 5,958 positions in this set that had at least 50 ORFs, we performed the anti-defence enrichment test. The same test was also conducted separately for each anti-defence category (namely anti-CRISPRs, anti-restriction genes and SOS inhibitors). The P values of all statistical analyses were corrected for multiple testing using the false discovery rate (FDR) (α = 0.001).
The leading region genes (ORFs in positions 1–28) of the 21,907 non-redundant potential conjugative sequences were clustered using MMseqs2 (ref. 66) (with sensitivity 7.5 and coverage 0.5). We examined the 300 largest gene families, which had more than 170 ORFs each (combined, they contained a total of 205,296 ORFs). Each family was aligned using MAFFT67 (v.7.475), and a pHMM was constructed from each alignment (Supplementary Data 1). Hmmsearch (e value threshold 10−6) was performed using these pHMMs against all potential conjugative sequences. To statistically test the enrichment of each gene family in the 1–28 ORF positions of the leading region, we performed a one-sided Fisher’s exact test and FDR correction. Forty-five of the 300 gene families were not significantly enriched in the leading regions (α = 0.001) and thus omitted from downstream analyses. The P value for each gene family after correction for multiple testing is specified in Supplementary Table 1.
The 188,655 proteins associated with families with at least five members were annotated on the basis of their DIAMOND80 hits (with e value < 10−6, coverage 0.6) against UniprotKB81. We examined the orientation of the ORFs relative to the oriT position in each of the significantly enriched gene families. The overall orientation of a gene family was defined on the basis of most of its ORFs. In families with ORFs that received different annotations, the most frequent annotation was used (Supplementary Table 1). For the 100 most prevalent families that were statistically enriched in the leading region, we also searched for known conserved domains using NCBI CDD82 (e < 10−6), NCBI-nr83 (e < 10−6) and HHpred84 (against the PDB85 and Pfam70 databases and e value threshold of 10−10).
Structural analysis
Structural prediction for 107,893 uncharacterized proteins smaller than 900 amino acids from gene families with at least five members was carried out using ESMfold86. The structure of 128 known anti-defence genes (115 anti-CRISPR and 13 anti-restriction genes) was conducted in the same manner. Subsequently, we used Foldseek87 to search the predicted structures against the UniProt50 Foldseek structural database, encompassing 53.7 million non-redundant proteins87, as well as against the database of the 128 anti-defence protein structures we predicted. Visualization of protein structures was performed with UCSF ChimeraX88.
Frpo and ssi promoter identification
To identify known Frpo/ssi sequences in the anti-defence islands, we created a BLAST73 dataset of all the gene regulatory regions with lengths of 50–350 bp in the leading regions of potential conjugative elements. We performed a BLAST search (BLAST+ v.2.10.0, e value threshold 10−6) against the five known Frpo/ssi sequences18,89 (Supplementary Table 2).
New candidate Frpo sequences were detected by seeking the consensus sequences of the −35, −10 (5′-TTGACA-3′ and 5′-TATAAT-3′, respectively) and the A + T rich UP-element located upstream of the −35 element90, in the intergenic regions of the islands represented in Fig. 2a–d. We then performed a BLAST search of the putative Frpo candidates from these islands against all the leading regions of our set of potential conjugative elements.
The DNA secondary structures of the Frpo/ssi elements were predicted using the RNAfold web server with the 2004 David H. Mathews model for DNA91,92. The graphical illustrations of the DNA structures (Fig. 2e,f) were produced using RNAtist93.
Bacterial strains, plasmids and growth
Bacterial strains, plasmids, gRNA sequences and oligonucleotides are detailed in Supplementary Table 4. The E. coli strains were routinely cultured in Luria–Bertani (LB) medium at 30 or 37 °C supplemented with antibiotics at the following concentrations: tetracycline (10 µg ml−1), streptomycin (100 µg ml−1), chloramphenicol (25 µg ml−1), kanamycin (50 µg ml−1) and carbenicillin (100 µg ml−1).
Gene cloning into the F plasmid was performed using lambda Red recombination94. Modified F plasmids were transferred to the background strain K12 MG1655 rpsL (StrepR) by means of conjugation (detailed below). The SpCas9 sequence was amplified from Addgene plasmid no. 101044, followed by cloning into the pD5 vector using Gibson Assembly. The insertion of gRNAs was performed by PCR amplification using primers that included the gRNA sequences and ligation of the products, followed by electroporation into DH10β and K12 MG1655 E. coli using a room temperature protocol95 and verified by Sanger sequencing.
Conjugation assays
Overnight cultures of recipient and donor cells grown on LB and selective antibiotics (tetracycline for the donors and kanamycin for recipients) were diluted 1:100 and grown to an optical density at 600 nm of 0.4. The cells were washed once with LB (2 min, 9,000 rpm) and resuspended with 50 µl of LB per conjugation. Donor (30 µl) and recipient (30 µl) cultures were mixed, and 20 µl of the mix was plated on an LB agar plate with 0.05 mM arabinose for the activation of SpCas9, then incubated for 2 h at 37 °C. Following incubation, cells were resuspended from the agar with 600 µl of 1× PBS, serially diluted 1:5 and plated on LB agar supplemented with 0.05 mM arabinose and the appropriate antibiotics to select for the recipient (R) or transconjugant (T) populations. The transconjugant frequency was quantified as T/(R + T). The conjugation efficiency was determined by calculating the transconjugant frequency per conjugation divided by the transconjugant frequency of the control, that is, the conjugation of the F plasmid without acrIIA4 into recipients expressing non-targeting SpCas9. The plate with transconjugant colonies (Fig. 3b) was photographed using PhenoBooth+ (Singer Instruments).
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All the analyses are based on publicly available, previously published datasets. The accessions of the analysed sequences are listed in Supplementary Table 5. The gene family numbers and ORF accessions are documented in Supplementary Table 6. The protein sequences of ORFs associated with gene family enriched in the leading region are provided in Supplementary Data 2. Profile HMMs produced as part of this study are available in Supplementary Data 1. Source data are provided with this paper.
Code availability
This paper does not report the development of original code.
References
von Wintersdorff, C. J. H. et al. Dissemination of antimicrobial resistance in microbial ecosystems through horizontal gene transfer. Front. Microbiol. 7, 173 (2016).
Carattoli, A. Plasmids and the spread of resistance. Int. J. Med. Microbiol. 303, 298–304 (2013).
Doron, S. et al. Systematic discovery of antiphage defense systems in the microbial pangenome. Science 359, eaar4120 (2018).
Getino, M. & de la Cruz, F. Natural and artificial strategies to control the conjugative transmission of plasmids. Microbiol. Spectr. https://doi.org/10.1128/microbiolspec.mtbp-0015-2016 (2018).
Gophna, U. et al. No evidence of inhibition of horizontal gene transfer by CRISPR–Cas on evolutionary timescales. ISME J. 9, 2021–2027 (2015).
Masai, H. & Arai, K. Frpo: a novel single-stranded DNA promoter for transcription and for primer RNA synthesis of DNA replication. Cell 89, 897–907 (1997).
Rodríguez-Beltrán, J., DelaFuente, J., León-Sampedro, R., MacLean, R. C. & San Millán, Á. Beyond horizontal gene transfer: the role of plasmids in bacterial evolution. Nat. Rev. Microbiol. https://doi.org/10.1038/s41579-020-00497-1 (2021).
Guglielmini, J., de la Cruz, F. & Rocha, E. P. C. Evolution of conjugation and type IV secretion systems. Mol. Biol. Evol. 30, 315–331 (2013).
Smillie, C., Garcillán-Barcia, M. P., Francia, M. V., Rocha, E. P. C. & de la Cruz, F. Mobility of plasmids. Microbiol. Mol. Biol. Rev. 74, 434–452 (2010).
Ares-Arroyo, M., Nucci, A. & Rocha, E. P. C. Identification of novel origins of transfer across bacterial plasmids. Preprint at https://doi.org/10.1101/2024.01.30.577996 (2024).
Ramsay, J. P. & Firth, N. Diverse mobilization strategies facilitate transfer of non-conjugative mobile genetic elements. Curr. Opin. Microbiol. 38, 1–9 (2017).
Ares-Arroyo, M., Coluzzi, C. & Rocha, E. P. C. Origins of transfer establish networks of functional dependencies for plasmid transfer by conjugation. Nucleic Acids Res. https://doi.org/10.1093/nar/gkac1079 (2022).
De La Cruz, F., Frost, L. S., Meyer, R. J. & Zechner, E. L. Conjugative DNA metabolism in Gram-negative bacteria. FEMS Microbiol. Rev. 34, 18–40 (2010).
Westra, E. R. et al. CRISPR-Cas systems preferentially target the leading regions of MOBF conjugative plasmids. RNA Biol. 10, 749–761 (2013).
Venturini, C. et al. Sequences of two related multiple antibiotic resistance virulence plasmids sharing a unique IS26-related molecular signature isolated from different Escherichia coli pathotypes from different hosts. PLoS ONE 8, e78862 (2013).
Takahashi, H., Shao, M., Furuya, N. & Komano, T. The genome sequence of the incompatibility group Iγ plasmid R621a: evolution of IncI plasmids. Plasmid 66, 112–121 (2011).
Bates, S., Roscoe, R. A., Althorpe, N. J., Brammar, W. J. & Wilkins, B. M. Y. Expression of leading region genes on IncI1 plasmid ColIb-P9: genetic evidence for single-stranded DNA transcription. Microbiology 145, 2655–2662 (1999).
Althorpe, N. J., Chilley, P. M., Thomas, A. T., Brammar, W. J. & Wilkins, B. M. Transient transcriptional activation of the IncI1 plasmid anti-restriction gene (ardA) and SOS inhibition gene (psiB) early in conjugating recipient bacteria. Mol. Microbiol. 31, 133–142 (1999).
Miyakoshi, M., Ohtsubo, Y., Nagata, Y. & Tsuda, M. Transcriptome analysis of zygotic induction during conjugative transfer of plasmid RP4. Front. Microbiol. 11, 1125 (2020).
Couturier, A. et al. Real-time visualisation of the intracellular dynamics of conjugative plasmid transfer. Nat. Commun. 14, 294 (2023).
Bernheim, A. & Sorek, R. The pan-immune system of bacteria: antiviral defence as a community resource. Nat. Rev. Microbiol. 18, 113–119 (2020).
Borges, A. L., Davidson, A. R. & Bondy-Denomy, J. The discovery, mechanisms, and evolutionary impact of anti-CRISPRs. Annu. Rev. Virol. 4, 37–59 (2017).
Goryanin, I. I. et al. Antirestriction activities of KlcA (RP4) and ArdB (R64) proteins. FEMS Microbiol. Lett. https://doi.org/10.1093/femsle/fny227 (2018).
Read, T. D., Thomas, A. T. & Wilkins, B. M. Evasion of type I and type II DNA restriction systems by Incl1 plasmid Collb-P9 during transfer by bacterial conjugation. Mol. Microbiol. 6, 1933–1941 (1992).
Jones, A. L., Barth, P. T. & Wilkins, B. M. Zygotic induction of plasmid ssb and psiB genes following conjugative transfer of Incl1 plasmid Collb-P9. Mol. Microbiol. 6, 605–613 (1992).
Virolle, C., Goldlust, K., Djermoun, S., Bigot, S. & Lesterlin, C. Plasmid transfer by conjugation in Gram-negative bacteria: from the cellular to the community level. Genes 11, 1239 (2020).
Garcillán-Barcia, M. P., Alvarado, A. & de la Cruz, F. Identification of bacterial plasmids based on mobility and plasmid population biology. FEMS Microbiol. Rev. 35, 936–956 (2011).
Fraikin, N., Couturier, A. & Lesterlin, C. The winding journey of conjugative plasmids toward a novel host cell. Curr. Opin. Microbiol. 78, 102449 (2024).
Stanley, S. Y. et al. Anti-CRISPR-associated proteins are crucial repressors of anti-CRISPR transcription. Cell 178, 1452–1464.e13 (2019).
Studier, F. W. Gene 0.3 of bacteriophage T7 acts to overcome the DNA restriction system of the host. J. Mol. Biol. 94, 283–295 (1975).
Zavilgelsky, G. B., Kotova, V. Y. & Rastorguev, S. M. Antimodification activity of the ArdA and Ocr proteins. Russ. J. Genet. 47, 139–146 (2011).
Fernández-López, C. et al. Mobilizable rolling-circle replicating plasmids from Gram-positive bacteria: a low-cost conjugative transfer. Microbiol. Spectr. https://doi.org/10.1128/microbiolspec.plas-0008-2013 (2014).
Soler, N. et al. Characterization of a relaxase belonging to the MOBT family, a widespread family in Firmicutes mediating the transfer of ICEs. Mob. DNA 10, 18 (2019).
Heilers, J.-H. et al. DNA processing by the MOBH family relaxase TraI encoded within the gonococcal genetic island. Nucleic Acids Res. 47, 8136–8153 (2019).
Murphy, J., Mahony, J., Ainsworth, S., Nauta, A. & Sinderen, D. Bacteriophage orphan DNA methyltransferases: insights from their bacterial origin, function, and occurrence. Appl. Environ. Microbiol. 79, 7547–7555 (2013).
Günthert, U. & Reiners, L. Bacillus subtilis phage SPR codes for a DNA methyltransferase with triple sequence specificity. Nucleic Acids Res. 15, 3689–3702 (1987).
Takahashi, N., Naito, Y., Handa, N. & Kobayashi, I. A DNA methyltransferase can protect the genome from postdisturbance attack by a restriction-modification gene complex. J. Bacteriol. 184, 6100–6108 (2002).
Fomenkov, A. et al. Plasmid replication-associated single-strand-specific methyltransferases. Nucleic Acids Res. 48, 12858–12873 (2020).
Petrova, V., Chitteni-Pattu, S., Drees, J. C., Inman, R. B. & Cox, M. M. An SOS inhibitor that binds to free RecA protein: the PsiB protein. Mol. Cell 36, 121–130 (2009).
Al Mamun, A. A. M., Kishida, K. & Christie, P. J. Protein transfer through an F plasmid-encoded type IV secretion system suppresses the mating-induced SOS response. mBio 12, e01629-21 (2021).
Roy, D., Huguet, K. T., Grenier, F. & Burrus, V. IncC conjugative plasmids and SXT/R391 elements repair double-strand breaks caused by CRISPR–Cas during conjugation. Nucleic Acids Res. 48, 8815–8827 (2020).
Shereda, R. D., Kozlov, A. G., Lohman, T. M., Cox, M. M. & Keck, J. L. SSB as an organizer/mobilizer of genome maintenance complexes. Crit. Rev. Biochem. Mol. Biol. 43, 289–318 (2008).
Pinilla-Redondo, R. et al. Discovery of multiple anti-CRISPRs highlights anti-defense gene clustering in mobile genetic elements. Nat. Commun. 11, 5652 (2020).
Gerdes, K., Christensen, S. K. & Løbner-Olesen, A. Prokaryotic toxin–antitoxin stress response loci. Nat. Rev. Microbiol. 3, 371–382 (2005).
Sutton, M. D., Smith, B. T., Godoy, V. G. & Walker, G. C. The SOS response: recent insights into umuDC-dependent mutagenesis and DNA damage tolerance. Ann. Rev. Genet. 34, 479–497 (2000).
Lodwick, D., Owen, D. & Strike, P. DNA sequence analysis of the IMP UV protection and mutation operon of the plasmid TP110: identification of a third gene. Nucleic Acids Res. 18, 5045–5050 (1990).
Kulaeva, O. I., Wootton, J. C., Levine, A. S. & Woodgate, R. Characterization of the umu-complementing operon from R391. J. Bacteriol. 177, 2737–2743 (1995).
Munoz-Najar, U. & Vijayakumar, M. N. An operon that confers UV resistance by evoking the SOS mutagenic response in streptococcal conjugative transposon Tn5252. J. Bacteriol. 181, 2782–2788 (1999).
Permina, E. A., Mironov, A. A. & Gelfand, M. S. Damage-repair error-prone polymerases of eubacteria: association with mobile genome elements. Gene 293, 133–140 (2002).
McLenigan, M. P., Kulaeva, O. I., Ennis, D. G., Levine, A. S. & Woodgate, R. The bacteriophage P1 HumD protein is a functional homolog of the prokaryotic UmuD′-like proteins and facilitates SOS mutagenesis in Escherichia coli. J. Bacteriol. 181, 7005–7013 (1999).
Goldsmith, M., Sarov-Blat, L. & Livneh, Z. Plasmid-encoded MucB protein is a DNA polymerase (pol RI) specialized for lesion bypass in the presence of MucA′, RecA, and SSB. Proc. Natl Acad. Sci. USA 97, 11227–11231 (2000).
Turlan, C., Prudhomme, M., Fichant, G., Martin, B. & Gutierrez, C. SpxA1, a novel transcriptional regulator involved in X-state (competence) development in Streptococcus pneumoniae. Mol. Microbiol. 73, 492–506 (2009).
Garriss, G. & Henriques-Normark, B. Lysogeny in Streptococcus pneumoniae. Microorganisms 8, 1546 (2020).
Del Grosso, M. et al. Macrolide efflux genes mef(A) and mef(E) are carried by different genetic elements in Streptococcus pneumoniae. J. Clin. Microbiol. 40, 774–778 (2002).
Croucher, N. J. et al. Horizontal DNA transfer mechanisms of bacteria as weapons of intragenomic conflict. PLoS Biol. 14, e1002394 (2016).
Norman, A., Hansen, L. H. & Sørensen, S. J. Conjugative plasmids: vessels of the communal gene pool. Philos. Trans. R. Soc. B. Biol. Sci. 364, 2275–2289 (2009).
Rubin, B. E. et al. Species- and site-specific genome editing in complex bacterial communities. Nat. Microbiol. 7, 34–47 (2022).
Araya, D. P. et al. Efficacy of plasmid-encoded CRISPR-Cas antimicrobial is affected by competitive factors found in wild Enterococcus faecalis isolates. Preprint at bioRxiv https://doi.org/10.1101/2022.03.08.483478 (2022).
Citorik, R. J., Mimee, M. & Lu, T. K. Sequence-specific antimicrobials using efficiently delivered RNA-guided nucleases. Nat. Biotechnol. 32, 1141–1145 (2014).
Rodrigues, M., McBride, S. W., Hullahalli, K.,Palmer, K. L. & Duerkop, B. A. Conjugative Delivery of CRISPR-Cas9 for the Selective Depletion of Antibiotic-Resistant Enterococci. Antimicrobial Agents and Chemotherapy 63, 10.1128/aac.01454-19 (2019).
Benson, D. A. et al. GenBank. Nucleic Acids Res. 41, D36–D42 (2013).
Mitchell, A. L. et al. MGnify: the microbiome analysis resource in 2020. Nucleic Acids Res. 48, D570–D578 (2020).
Hyatt, D. et al. Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC Bioinf. 11, 119 (2010).
Seemann, T. Prokka: rapid prokaryotic genome annotation. Bioinformatics 30, 2068–2069 (2014).
Miller, D., Stern, A. & Burstein, D. Deciphering microbial gene function using natural language processing. Nat. Commun. 13, 5731 (2022).
Steinegger, M. & Söding, J. MMseqs2 enables sensitive protein sequence searching for the analysis of massive data sets. Nat. Biotechnol. 35, 1026–1028 (2017).
Katoh, K., Misawa, K., Kuma, K. & Miyata, T. MAFFT: a novel method for rapid multiple sequence alignment based on fast Fourier transform. Nucleic Acids Res. 30, 3059–3066 (2002).
Eddy, S. R. Accelerated profile HMM searches. PLoS Comput. Biol. 7, e1002195 (2011).
Garcillán-Barcia, M. P., Redondo-Salvo, S., Vielva, L. & de la Cruz, F. in Horizontal Gene Transfer: Methods and Protocols. Methods in Molecular Biology vol. 2075 (ed. de la Cruz, F.) 295–308 (Humana, New York, 2020).
Mistry, J. et al. Pfam: the protein families database in 2021. Nucleic Acids Res. 49, D412–D419 (2020).
Li, X. et al. oriTfinder: a web-based tool for the identification of origin of transfers in DNA sequences of bacterial mobile genetic elements. Nucleic Acids Res. 46, W229–W234 (2018).
Zrimec, J. Multiple plasmid origin-of-transfer regions might aid the spread of antimicrobial resistance to human pathogens. MicrobiologyOpen 9, e1129 (2020).
Camacho, C. et al. BLAST+: architecture and applications. BMC Bioinf. 10, 421 (2009).
Li, W. & Godzik, A. CD-HIT: a fast program for clustering and comparing large sets of protein or nucleotide sequences. Bioinformatics 22, 1658–1659 (2006).
Letunic, I. & Bork, P. Interactive Tree Of Life (iTOL) v5: an online tool for phylogenetic tree display and annotation. Nucleic Acids Res. 49, W293–W296 (2021).
Ciccarelli, F. D. et al. Toward automatic reconstruction of a highly resolved tree of life. Science 311, 1283–1287 (2006).
ggtreeExtra: an R package to add geom layers on circular or other layout tree of ‘ggtree’ (Bioconductor, 2022).
Kanehisa, M. & Goto, S. KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res. 28, 27–30 (2000).
Riadi, G., Medina-Moenne, C. & Holmes, D. S. TnpPred: a web service for the robust prediction of prokaryotic transposases. Int. J. Genomics 2012, 678761 (2012).
Buchfink, B., Xie, C. & Huson, D. H. Fast and sensitive protein alignment using DIAMOND. Nat. Methods 12, 59–60 (2015).
The UniProt Consortium. UniProt: the Universal Protein Knowledgebase in 2023. Nucleic Acids Res. 51, D523–D531 (2023).
Wang, J. et al. The conserved domain database in 2023. Nucleic Acids Res. 51, D384–D388 (2023).
Sayers, E. W. et al. Database resources of the National Center for Biotechnology Information in 2023. Nucleic Acids Res. 51, D29–D38 (2023).
Soding, J., Biegert, A. & Lupas, A. HHpred interactive server for protein homology detection and structure prediction. Nucleic Acids Res. 33, W244–W248 (2005).
Berman, H. M. et al. The Protein Data Bank. Nucleic Acids Res. 28, 235–242 (2000).
Lin Z. et al. Evolutionary-scale prediction of atomic-level protein structure with a language model. Science 379, 1123–1130 (2023).
van Kempen, M. et al. Fast and accurate protein structure search with Foldseek. Nat. Biotechnol. 42, 243–246 (2024).
Meng, E. C. et al. UCSF ChimeraX: tools for structure building and analysis. Protein Sci. 32, e4792 (2023).
Nomura, N. et al. Identification of eleven single-strand initiation sequences (SSI) for priming of DNA replication in the F, R6K, R100 and ColE2 plasmids. Gene 108, 15–22 (1991).
Ross, W. et al. A third recognition element in bacterial promoters: DNA binding by the α subunit of RNA polymerase. Science 262, 1407–1413 (1993).
Gruber, A. R., Lorenz, R., Bernhart, S. H., Neuböck, R. & Hofacker, I. L. The Vienna RNA Websuite. Nucleic Acids Res. 36, W70–W74 (2008).
Lorenz, R. et al. ViennaRNA package 2.0. Algorithms Mol. Biol. 6, 26 (2011).
Jossinet, F. RNArtistCore: a Kotlin DSL and library to create and plot RNA 2D structures. GitHub https://github.com/fjossinet/RNArtistCore (2023).
Yu, D. et al. An efficient recombination system for chromosome engineering in Escherichia coli. Proc. Natl Acad. Sci. USA 97, 5978–5983 (2000).
Tu, Q. et al. Room temperature electrocompetent bacterial cells improve DNA transformation and recombineering efficiency. Sci. Rep. 6, 24648 (2016).
Malaka De Silva, P. et al. A tale of two plasmids: contributions of plasmid associated phenotypes to epidemiological success among Shigella. Proc. R. Soc. B. Biol. Sci. 289, 20220581 (2022).
Darphorn, T. S. Antibiotic resistance plasmid composition and architecture in Escherichia coli isolates from meat. Sci. Rep. 13, 2136 (2021).
Thisted, T. & Gerdes, K. Mechanism of post-segregational killing by the hok/sok system of plasmid R1. J. Mol. Biol. 223, 41–54 (1992).
Gerdes, K. The parB (hok/sok) locus of plasmid R1: a general purpose plasmid stabilization system. Nat. Biotechnol. 6, 1402–1405 (1988).
Le Rhun, A. et al. Profiling the intragenic toxicity determinants of toxin–antitoxin systems: revisiting hok/Sok regulation. Nucleic Acids Res. 51, e4 (2023).
Loh, S. M., Cram, D. S. & Skurray, R. A. Nucleotide sequence and transcriptional analysis of a third function (Flm) involved in F-plasmid maintenance. Gene 66, 259–268 (1988).
Birge, E. A. Bacterial and bacteriophage genetics. VDOC.pub Library https://vdoc.pub/documents/bacterial-and-bacteriophage-genetics-5rte3vvpnkt0 (2006).
Her, H.-L., Lin, P.-T. & Wu, Y.-W. PangenomeNet: a pan-genome-based network reveals functional modules on antimicrobial resistome for Escherichia coli strains. BMC Bioinf. 22, 548 (2021).
Uribe, R. V. et al. Discovery and characterization of Cas9 inhibitors disseminated across seven bacterial Phyla. Cell Host Microbe 25, 233–241.e5 (2019).
Davidson, A. R. et al. Anti-CRISPRs: protein inhibitors of CRISPR-Cas systems. Annu. Rev. Biochem. 89, 309–332 (2020).
Acknowledgements
We thank C. Lesterlin and E. Westra for providing strains. Special thanks to G. Segal and A. San Millan for their valuable inputs on the experimental methodology and analysis. We thank T. Parket for his bioinformatic analyses. We are also grateful to A. Eldar, E. Ron, A. Stern and U. Gophna for their helpful discussions and comments on the paper. This research was partly supported by the Israel Science Foundation (grant number 1692/18) and the Edmond J. Safra Center for Bioinformatics at Tel-Aviv University.
Author information
Authors and Affiliations
Contributions
B.S. and D.B. conceived and designed the study, performed the data analysis and wrote the paper. B.S., D.B., K.M. and S.Y.C. conducted the conjugation experiments. B.S., D.B. and M.B.H. performed the protein structural analysis.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Christian Lesterlin and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Workflow overview.
a, All assembled genomes and metagenomes available in NCBI’s61 and EBI’s62 databases were analysed. In the first phase, we considered only sequences explicitly annotated as plasmids. In the second phase, we included all sequences that contained a detectable relaxosome component gene in proximity to a known oriT sequence. We termed the combined set of the two phases “potential conjugative elements”. Redundant elements of this set were omitted based on sequence similarity. The non-redundant sequences were then classified according to their MOB types. b, We mapped to the potential conjugative elements the leading and lagging regions, known anti-defence genes (anti-restriction, anti-CRISPR, and anti-SOS), and transfer-related genes. We focused on the genes enriched in the leading region and characterized them further. These gene families were classified based on sequence and structural similarity, into the following groups: anti-defence, putative anti-defence, DNA-methyltransferases, SSB genes, toxin-antitoxin genes, uncharacterized genes, and other functional families.
Extended Data Fig. 2 Frequency of anti-defence genes relative to the origin of transfer (oriT).
a, Anti-defence gene frequency in 2,259 non-redundant sequences annotated as plasmids. The x-axis shows ORF indices relative to the oriT, with 0 representing the first ORF in the leading region. Positions that were represented in at least 150 sequences annotated as plasmids are plotted. The y-axis indicates the average frequency of anti-defence genes (combining SOS inhibition, anti-restriction, and anti-CRISPR genes) over a five ORF window. b, Analysis of 22,897 out of 26,327 non-redundant potential conjugative elements that could be reliably mapped to a MOB type. The x-axis shows ORF indices relative to the oriT, with 0 representing the first ORF in the leading region. The y-axis indicates the average frequency of anti-defence genes (combining SOS inhibition, anti-restriction, and anti-CRISPR genes) over a five-ORF window, with frequencies for each MOB type colour-coded and stacked. Only positions represented in at least 1,000 sequences are shown. c, Anti-defence gene frequency within the 21,907 potential conjugative elements retrieved from genomic and metagenomic databases (MOB types F, P1, Q, V, H, B). Only positions represented in at least 50 sequences are shown.
Extended Data Fig. 3 Phylogenetic distribution of the analysed conjugative elements.
The phylogenetic distribution of the 13,738 non-redundant plasmids and potential conjugative elements. This set excluded 8,169 elements originating from metagenomes and sequences that could not be reliably mapped to the tree. The bacterial tree of life was acquired from iTOL75, with bars colour-coded according to phyla, representing the conjugative element count on a log10 scale.
Extended Data Fig. 4 Structural comparison of known anti-CRISPRs and anti-CRISPR candidates identified based on their location and structural similarity.
a, AcrIIA8 anti-CRISPR (NCBI accession VDB32352.1) compared to a putative anti-CRISPR found in a conjugative element from a human gut metagenome (Mgnify analysis accession ERZ1741958, NODE_63). b, Anti-CRISPR AcrIIA8 (NCBI Protein accession VDB32352.1) compared to a putative anti-CRISPR found in a conjugative element of Staphylococcus epidermidis (NCBI accession VYVG01000002.1). c, Anti-CRISPR AcrIIA1 (NCBI accession WP_003722518.1) compared to a putative anti-CRISPR found in a conjugative element from a human gut metagenome (NCBI accession BABC01000244.1). d, Anti-CRISPR AcrVA5 (NCBI accession WP_046699157.1) compared to a putative anti-CRISPR found in a conjugative element of Salmonella enterica (NCBI accession AAEVVI010000002.1).
Extended Data Fig. 5 Additional examples of anti-defence islands from various bacterial hosts.
a–d, Islands from leading regions of conjugative elements in: (a) Streptomyces sp. DJ (NCBI accession PKSK01000906.1), (b) Enterococcus durans (NCBI accession VMRQ01000005.1), (c) Shigella sonnei (NCBI accession CM012291.1) and (d) Klebsiella variicola (NCBI accession CP008701.1). The oriT location is marked in red on the left. Genes are coloured-coded by functional category: anti-defence (red), DNA-methyltransferase (MTase, peach), toxin-antitoxin genes (orange), ssDNA-binding protein (SSB, yellow), mobility (transfer genes, blue), other (gene without known association to anti-defence, teal). Frpo promoters are indicated by an arrow. Asterisks (*) indicate unannotated genes with a putative anti-defence function. e, Position distribution of anti-defence genes at each ORF position relative to umuD homologues (set as position 0) in the leading region. f, Similar analysis for umuC homologues. In cases of multiple umuD/umuC genes in the same leading region, the homologue closest to the oriT was used as reference.
Extended Data Fig. 6 Sequences and predicted secondary structures of Frpo promoters.
a, Candidate Frpo* sequences found in S. enterica conjugative elements (Fig. 2a), showing limited similarity to known Frpo. Promoter elements (−10, −35, and UP) are indicated by red boxes. b, Frpo identified upstream of an SSB protein in S. marcescens plasmid (see Fig. 2b). c, Candidate Frpo’ detected in a conjugative element from an insect gut metagenome (Fig. 2c). Sequences in b,c exhibit high sequence similarity to known Frpo sequences.
Supplementary information
Supplementary Discussion
Discussion on the potential roles of toxin–antitoxin genes in the leading region of plasmids and their establishment.
Supplementary Table 1
Statistical analysis for 300 largest protein families, alongside sequence-based annotation and structural analysis of 100 largest protein families, and unannotated families enriched in the leading region.
Supplementary Table 2
Frpo-like sequences used in this study.
Supplementary Table 3
Anti-defence and mobility genes used in this study.
Supplementary Table 4
Strains, plasmids and oligonucleotides used in this study.
Supplementary Table 5
List of 27,677 non-redundant plasmids and potential conjugative elements retrieved from genomic and metagenomic databases, and 21,907 non-redundant elements after excluding MOB types T, P2 and C.
Supplementary Table 6
ORF accessions of genes associated with families of at least five members enriched in the leading region.
Supplementary Data 1
pHMMs for the largest 300 gene families enriched in the leading region.
Supplementary Data 2
Protein sequences associated with families enriched in the leading region.
Supplementary Data 3
Sequence of the Frpo-acrIIA4-cat construct used in this study.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Samuel, B., Mittelman, K., Croitoru, S.Y. et al. Diverse anti-defence systems are encoded in the leading region of plasmids. Nature 635, 186–192 (2024). https://doi.org/10.1038/s41586-024-07994-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41586-024-07994-w
This article is cited by
-
CRISPR–Cas therapies targeting bacteria
Nature Reviews Bioengineering (2025)
-
Interactions and evolutionary relationships among bacterial mobile genetic elements
Nature Reviews Microbiology (2025)
-
Expanding the diversity of origin of transfer-containing sequences in mobilizable plasmids
Nature Microbiology (2024)
-
Anti-defence islands in plasmids
Nature Reviews Microbiology (2024)
